AI 내부 작동 원리에 대한 이해와 불확실성 측정을 연결한 새로운 시도
포스텍 연구팀이 거대언어모델(LLM)이 동일한 질문에도 서로 다른 답변을 내놓는 원인을 분석하고 AI의 불확실성을 원인별로 구분해 진단할 수 있는 방법을 개발했다.
 |
| ▲ 포스텍 연구진. 왼쪽부터 인공지능대학원 이남훈 교수, 통합과정 정진석, 석사과정 송민경·정현지 씨. [포스텍 제공] |
포스텍은 인공지능대학원 이남훈 교수, 통합과정 정진석, 석사과정 송민경·정현지 씨 연구팀이 거대언어모델(LLM) 예측에 담긴 불확실성을 원인별로 분리해 측정하는 방법론을 개발했다고 1일 밝혔다.
이 연구는 2일부터 7일까지 미국 샌디에이고에서 열리는 자연어처리 및 전산언어학 분야의 국제 학회인 'ACL 2026'에 구두 발표 논문으로 채택됐다.
챗GPT에 같은 질문을 물어봐도 답이 조금씩 달라질 때가 있다. 정말 알고 답한 것일까, 잘 모르고 있는 것일까?
챗GPT 같은 거대언어모델(LLM)은 몇 개의 예시만으로 새로운 작업을 수행하는 '맥락 내 학습' 능력이 있다. 그러나 같은 질문에도 답변이 달라지거나 틀린 정보를 사실처럼 제시하는 경우가 있어 AI의 판단을 얼마나 신뢰할 수 있는지가 중요한 과제로 떠오르고 있다.
AI의 불확실성은 두 가지 원인에서 비롯된다. 질문이나 데이터 자체가 모호해 하나는 누구라도 답하기 어려운 경우와 AI가 관련 지식이나 정보를 충분히 갖고 있지 못한 경우다. 이 둘은 해결 방법이 다르지만 기존 방법으로는 명확히 구분하기 어려웠다.
연구팀은 AI 모델 내부를 직접 분석하는 접근법을 개발했다. 접근법은 '셀프-함수 벡터'라는 개념으로 모델 내부 활성값을 활용해 AI가 예시를 통해 학습한 핵심 개념을 벡터 형태로 표현하는 기술이다.
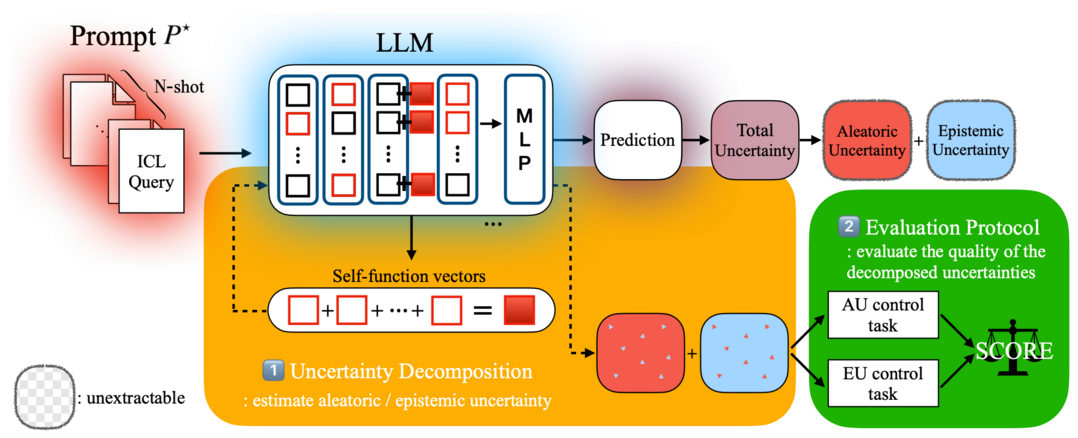 |
| ▲ 거대 언어모델의 내부 표현을 분석해 예측의 불확실성을 두 종류로 분리하고 그 분리 성능을 검증하는 평가 체계를 제시한 연구 개념도. [포스텍 제공] |
이 벡터를 활용해 데이터의 모호함에서 비롯된 불확실성과 모델의 지식 부족에서 발생한 불확실성을 효과적으로 분리해 측정했다. 이 과정에서 AI 내부 작동 원리를 분석하는 '기계론적 해석가능성' 연구와 베이지안 추론 이론을 결합해 새로운 분석 틀도 함께 제시했다.
이와 함께 이 기술을 객관적으로 검증하는 평가 체계도 개발했다. 데이터 모호함과 모델의 지식 부족 정도를 각각 독립적으로 조절하는 방식으로 환경을 설계해 불확실성을 정량적으로 평가할 수 있도록 했다.
연구팀의 방법은 70억~700억 개 규모 모델에서도 일관된 성능을 보였다. 두 종류의 불확실성에 대해 서로 다른 반응 패턴을 보이며 기존보다 명확하게 분류함을 정량적으로 입증했다.
특히 이 기술은 AI 환각 탐지에서도 우수한 성능을 보이며 신뢰할 수 있는 AI 개발에 활용될 가능성을 확인했다.
이남훈 교수는 "AI 내부 작동 원리에 대한 이해와 불확실성 측정을 연결한 새로운 시도"라며 "AI가 왜 확신하지 못하는지를 설명할 수 있게 되면 더욱 안전하고 신뢰할 수 있는 AI 개발에 중요한 기반이 될 것"이라고 말했다.
KPI뉴스 / 장영태 기자 3678jyt@kpinews.kr
[ⓒ KPI뉴스. 무단전재-재배포 금지]




